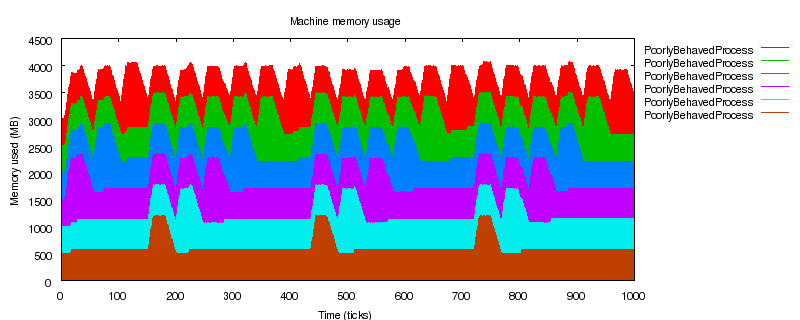
Current Situation
For this discussion, I have chosen to examine memory usage because memory
is a sufficiently scare resource which is quite easy to measure. Another
scare resource of interest might be I/O latency (the time between issuing
an I/O request until when the kernel begins to service that request).
However, measuring such delays is much more complex and begins to deal with
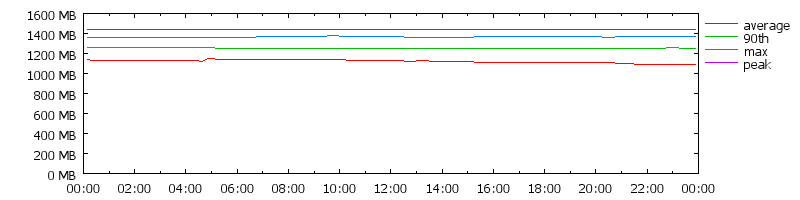
Quality of Service (QoS) issues. Figure 1 shows the typical memory usage
patterns over the course of 24 hours for a large (few thousand machine)
cluster. This cluster has not yet reached capacity, however, there is
still a significant difference between reserved and used memory. Note that
any blip in total memory is generally caused by more racks of machines
being powered up.
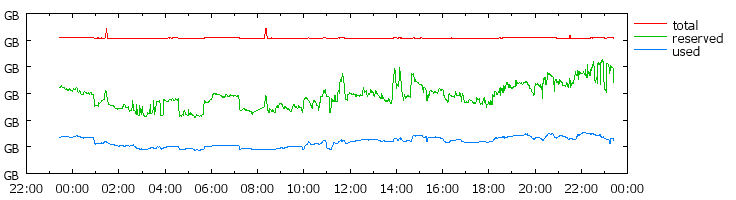
Figure 1: Memory usage of a typically loaded cluster
(note: measurements taken from a Google cluster with consent.
The scale is omitted, but on the order of the 10000s of GB)
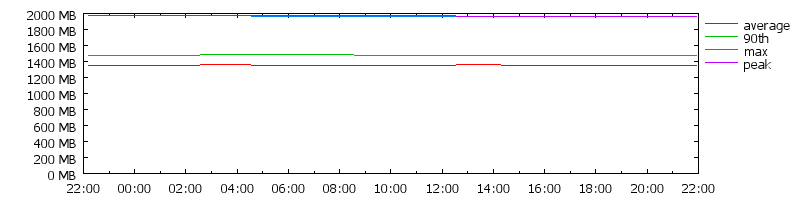
In contrast, figure 2 depicts a very overloaded cluster in the sense that
it cannot readily accept new jobs. However, even though the scheduler
would not be able to guarantee resources to incoming job requests, there is
a significant amount of memory unused. Approximately 20% of the total
memory of the cluster is actually being used by running processes, 70% is
allocated but unused, and the remaining 10% is fragmented. Such a cluster
could be regarded as a degenerate case, but there seem to be many clusters
who's memory usage look like figure 1 or a hybrid between figure 1 and
figure 2. This suggests that clusters tend towards significant
under-utilization of memory.
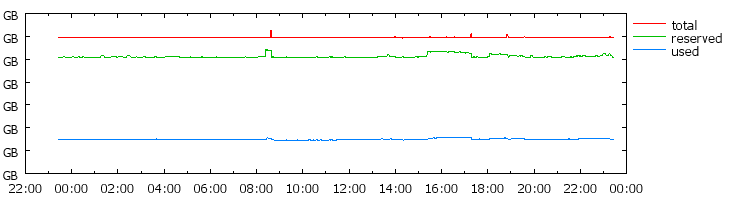
Figure 2: Memory usage of a over loaded cluster
(note: measurements taken from a Google cluster with consent.
The scale is omitted, but on the order of the 10000s of GB)
The large unused amount of memory in figure 2 is due to gross
over-estimations of the resource needs of many tasks. However, even if
there were only a negligible difference between used and reserved, there
would still be a significant amount of fragmented memory. Upon measuring
clusters like figure 1, I found that an average machine had about 25% of
its memory in use, and about 50% fragmented. These numbers backup the
situation depicted in the figure. Further, since these machines had an
average of 4.5GB of memory, the 50% fragmentation left plenty of room for
another process. However, in clusters like figure 2, about 25% memory is
in use, but now only 5% - 10% is fragmented. In this case, the remaining
fragmented memory only represents a few hundred MB of memory, and there
aren't too many tasks which can fit in such a small memory footprint.
Fortunately, well over 60% of the memory on these machines (in both
clusters) is free, so other tasks could be scheduled into the free memory
if the eviction policies of the cluster manager where modified. I will
consider how we can maximize overall memory usage across the cluster by
using better scheduling techniques and by placing "small" tasks in
fragmented or free memory.
Figure 1: Memory usage of a typically loaded cluster
(note: measurements taken from a Google cluster with consent.
The scale is omitted, but on the order of the 10000s of GB)
Figure 2: Memory usage of a over loaded cluster
(note: measurements taken from a Google cluster with consent.
The scale is omitted, but on the order of the 10000s of GB)